003Decentralized Networking
Satori Network
Emergency infrastructure rescue that took a buckling decentralised AI network to 100% uptime.
The problem
Satori's decentralised AI prediction network grew so fast that its central components were going down multiple times a day. They brought us in as emergency consultants to diagnose the failures and chart a way out.
What we built
We worked through it tactically over a couple of weeks. First we added exception and performance monitoring, because you can't fix what you can't measure. Then we dockerised the platform and put it behind a load balancer with horizontally scaled nodes, rewrote and indexed expensive SQL queries, and right-sized provisioning to around 75% CPU and memory. We turned on continuous monitoring with automatic alerting and a commitment to respond within 15 minutes, day or night, then built out a longer-term architectural strategy with scenario planning and drill runs.
The outcome
The network reached 100% uptime shortly after we engaged, with outages cut from multiple per day to zero. We stayed on to implement the long-term architecture and remain on hand if issues come up.
AI woven through
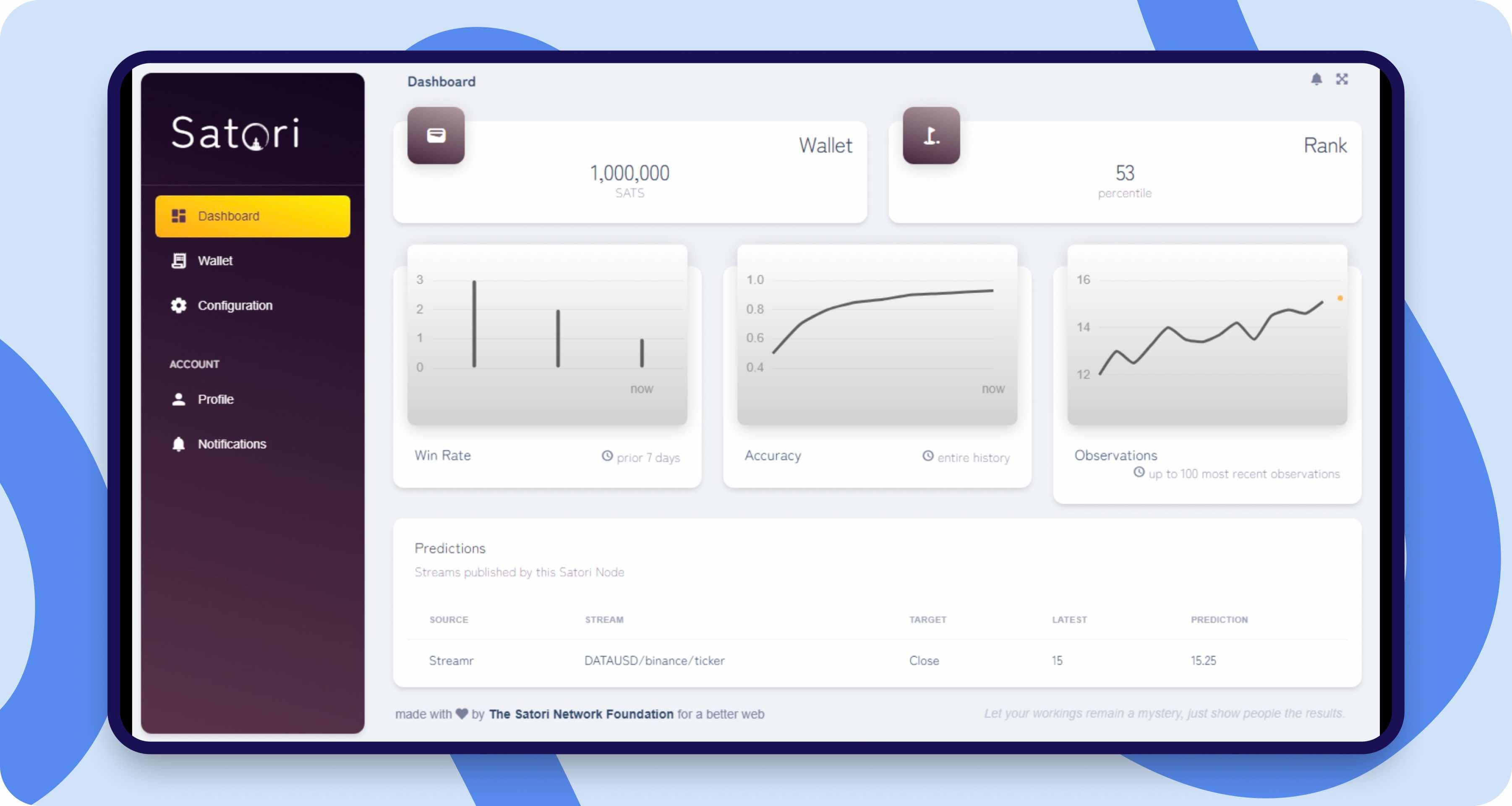
The network itself is a decentralised mesh of nodes (electrons) that contribute AI predictions, which is what we kept online; our work was on the infrastructure beneath it rather than the AI.
“You can't fix what you can't measure.”
Screens
Build with us
Want something like Satori Network? Let's build it.
Bring us an idea, a half-built product, or a problem you can't find the right team for. We'll come back with a plan, a fixed price, and a way to start.